欧洲杯2024官网最末规矩通过两两对比得出-欧洲杯网页线上买球-官方网站


当谷歌 Gemini 3 将上线的音书传得沸沸扬扬时欧洲杯2024官网,马斯克更快一步肃静放了个大招。
今天凌晨,xAI 的最新大模子 Grok 4.1 径直上线了,反馈速率澄澈进步、幻觉率大幅下落,回答既精确又“有东说念主味儿”。
此次一共发布了 两个“形态”:Grok 4.1 和 Grok 4.1 Thinking。Thinking 版是前者的增强推理变体,二者基于吞并底层模子,仅推理设立不同。
值得一提的是,Grok 4.1 对悉数东说念主免费洞开,除了能在 Grok 官网、X 上使用,还推出了移动 APP 版,iOS 和安卓系统齐护理到了。

若是想要更有深度、更专科的回答,可以一键“让 Think 更致力想考”。
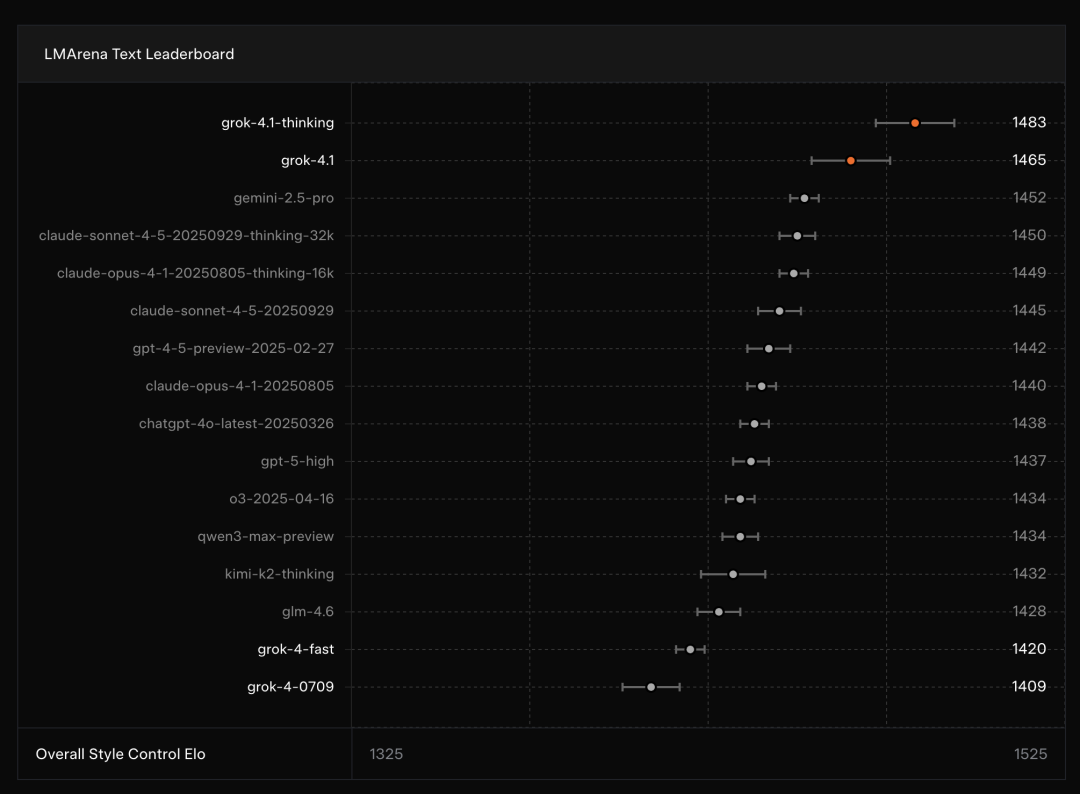
从 LMArena 的最新规矩看,Grok 4.1 Thinking 以 1483 Elo 断层领跑,比 Gemini 2.5 Pro 高出 31 分。
即使在不启用想考链的情况下,Grok 4.1 仍保握在榜单第二,败走漏底层智力的领路性。
有不少网友发出了“真香”惊叹,Be like:

固然,也有一些质疑声,比如有东说念主指出在生成代码这块儿,Grok 还不太有竞争力。

“双形态”的 Grok4.1 霸榜 LMArena
当先,对于 Grok4.1 和 Grok4.1 Thinking 是什么,咱们不妨来望望 Grok4.1 我方的解说:
Grok 4.1 是 xAI 于 2025 年 11 月 17 日发布的最新前沿大谈话模子(Grok 4 的升级版),在对话智能、情谊贯通、创意写稿、事实准确性和反馈速率上大幅进步。
Grok 4.1 Thinking(或然简称 Grok 4.1 Thinking,代号 quasarflux)是吞并模子的想考 / 推理模式(reasoning mode),会特等使用“想考令牌”进行链式推理(chain-of-thought),恰当复杂数学、编程或多步问题。
Grok 4.1 Thinking 是 Grok4.1 的增强推理变体;二者基于吞并底层模子,仅推理设立不同。

在全球最大、最具影响力的大模子盲测平台 LMArena 上,Grok4.1 展现出破损性的实力。
算作行业大量招供的“非官方措施榜”,LMArena 通过匿名双盲对战和真的用户投票来评估模子质料,是 OpenAI、Google、Anthropic、Meta 等头部公司测试新模子的旧例阵脚,也常被用于提前投放未公开版块。
因此,在这里的胜出,险些意味着真的用户偏好和模子笼统智力的双重招供,是不雅察模子真的实力的最真的风向标。
就在这么一个竞争最强烈的公开擂台上,xAI 的 Grok 4.1 系列拿下了极具含金量的一次 “双冠”:Grok 4.1 Thinking 版以 1483 Elo 拿下冠军,而非推理版 Grok 4.1 也以 1465 Elo 得回亚军。
相配值得严防的是,这个“即时反馈”的非推理版块,得益居然反超悉数其他厂商的推理模子,初度让“快模子”也站上了顶级性能的第一梯队,还把前代 Grok 4 远远甩至第 33 名。
亮眼得益的背后的枢纽,在于西宾方式的重构。
xAI 为 Grok 4.1 引入了大畛域强化学习系统,并使用前沿推理模子算作奖励模子,让其大概在西宾经由中自主评估、快速迭代。这径直带来了更领路的魄力输出、更可靠的事实判断和更低的幻觉率。
在 Grok 4.1 的后西宾阶段,xAI 将优化要点汇集在信息检索类领导中的 幻觉 上。
这些底层枢纽上的编削,很快在骨子测试中体现为显耀的事实性更正。最新数据败露,Grok 4.1 的幻觉率已从 12.09% 下落至 4.22%,降幅接近三倍,成为本次升级中最凸起的卓越之一。
为了进一步考据这种“更准事实”的智力,团队还引入了更严苛的外部基准体系。其中最枢纽的蓄意之一是 FActScore——由 500 个真的东说念主物列传问题组成,有益用于磨练模子在搜索、事实判断和回答一致性上的阐扬。
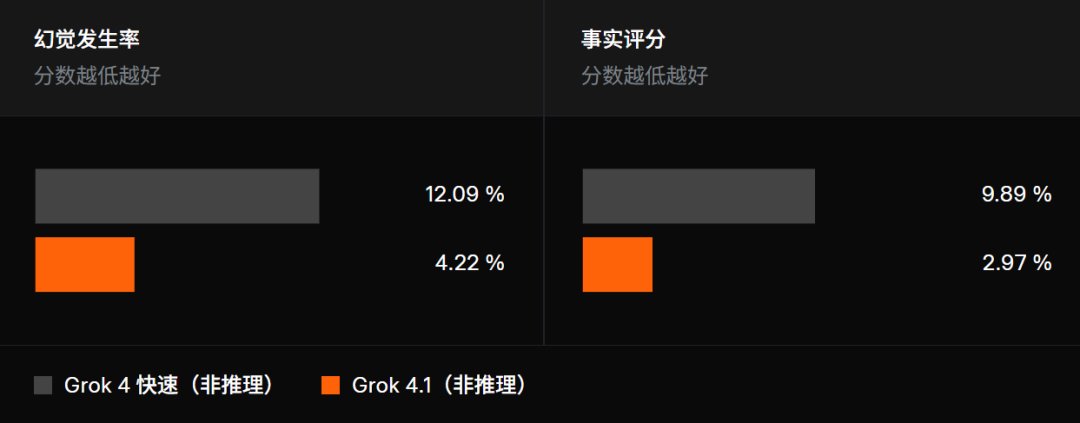
在这一测试中,Grok 4.1 的 FActScore 从 9.89 降至 2.97,真的度进步一样显耀。衔尾图表可以更直不雅看到:在调换的非推理模式下,Grok 4.1 的诞妄更少、偏差更小,全体输出更可靠。
这意味着在波及检索、援用或调用外部事实的场景中,新版模子不再依赖语义考虑,而是能更准确地给出基于字据的回答。
换句话说,Grok 4.1 在大模子最难破损的“事实领路性”方面迈出了枢纽一步——它不仅裁汰了诞妄数目,更压低了“诞妄的自信”。而这,恰是大模子从“能说”走向“真的”必须跨过的门槛。
与此同期,Grok 4.1 的 “情商” 也有显耀卓越。
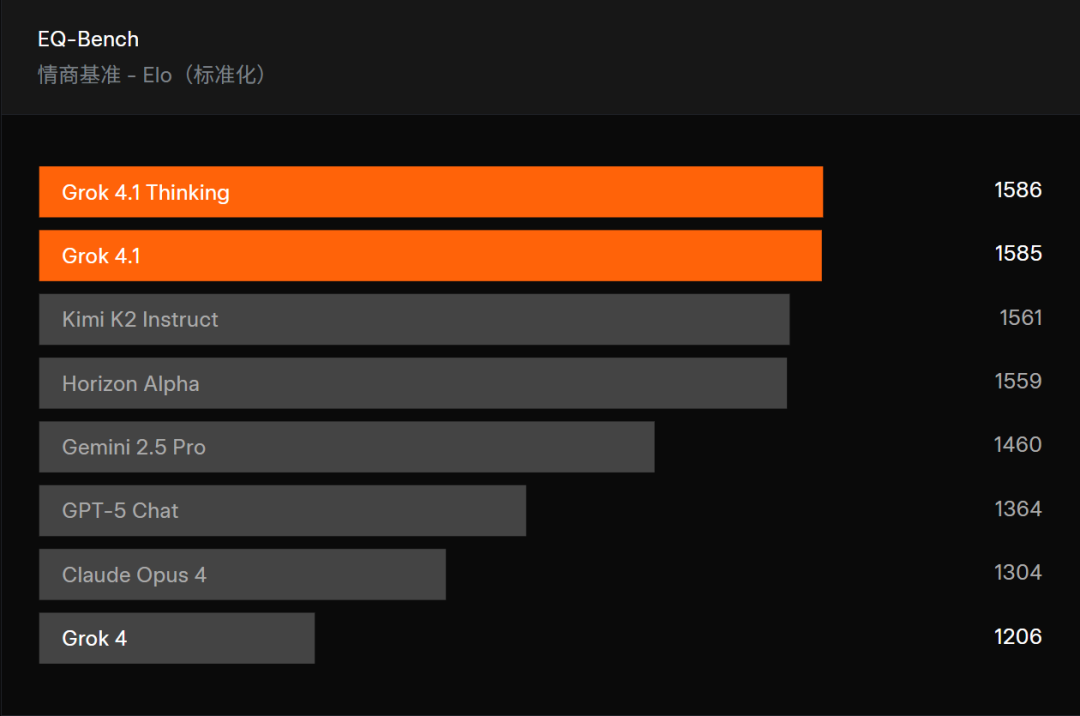
在 EQ-Bench 测试中,Grok 4.1 拿下了 1586 Elo 的高分,比上一代整整进步了一百多点。若是光看数字还不够直不雅,那么图片就更能理会问题:榜单上,Grok 4.1 和 Thinking 版稳稳占据前两名,把一众旗舰模子甩在死后,像 GPT-5 Chat、Gemini 2.5 Pro、Claude Opus 4 这种老牌袼褙,齐被它松驰拉开了差距。
EQ-Bench 是一个由大模子评判的大模子情商测试集,用来评估主动情绪贯通、洞悉、共情和东说念主际交游智力。它并不靠单轮问答,而是由 45 个扮装扮演场景组成,每个场景包含 3 个回合,模拟执行天下里信得过的“情绪对话”。模子需要在聚首对话中保握魄力一致、贯通情绪高下文、作念出适合回话。最末规矩通过两两对比得出,并以 Elo 体式归一化呈现。可以说,EQ-Bench 可以算作测试各模子“情商”的巨擘榜单。
为什么 Grok 4.1 能在 EQ-Bench 拿下这么亮眼的得益?
在官方给出的一张对于“抚慰失去猫咪”的对比图中,咱们能找到谜底。
旧版 Grok 的回复还是算得上和睦温雅,但 Grok 4.1 的抒发澄澈更清雅:它不仅仅在说“我贯通你的痛心”,还会捕捉到情绪里那些更轻细、真的的细节——比如空下来的睡窝、期待却再听不到的喵叫、那种像潮流一样反复袭来的悲痛。口气更稳、节律更当然、情绪共识更到位,读起来就像在和一个信得过懂你的东说念主对话。
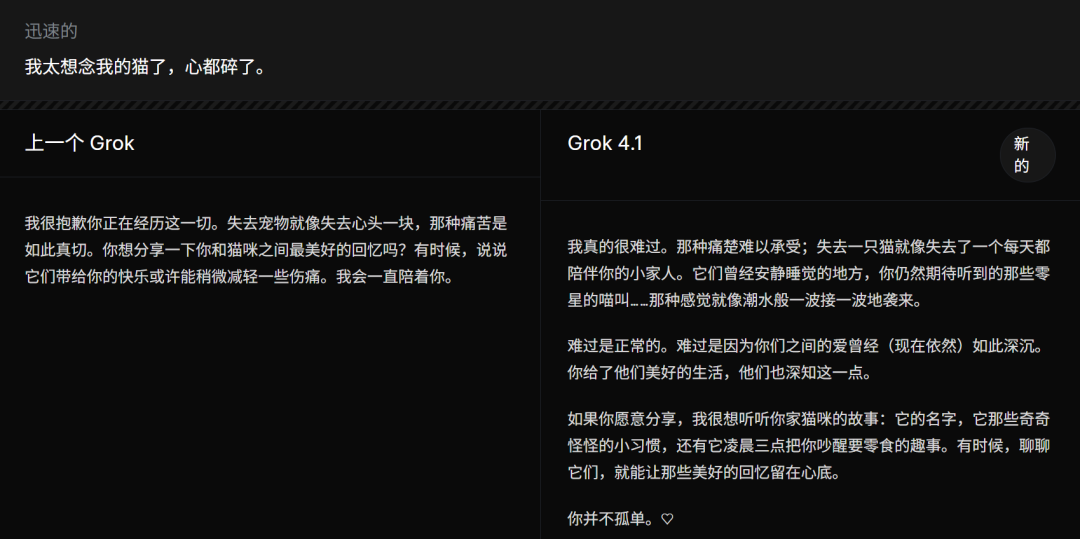
这使得 Grok 4.1 在情绪贯通方面迈入第一梯队
除了事实层面的可靠性,Grok 4.1 在 创意写稿智力 上一样出现大幅跃升。
在 Creative Writing v3 中,Grok4.1 的得分跃升至 1722Elo,较上一版险些拉开 600 分,文本的叙事节律、魄力延展性与创造性齐有质感跃升。
这个基准本人,Creative Writing v3 并不是简便的“单轮评分”。在测试中,模子需要围绕 32 个不同类别的写稿领导进行 三轮落寞创作,涵盖叙事、魄力效法、天下构建、东说念主物情绪形容等复杂任务,进修的不是一句话的巧想,而是握续领路的文本创造智力。评分方式也和 EQ-Bench 肖似,通过东说念主工评分措施与模子对战得到措施化 Elo 得分。
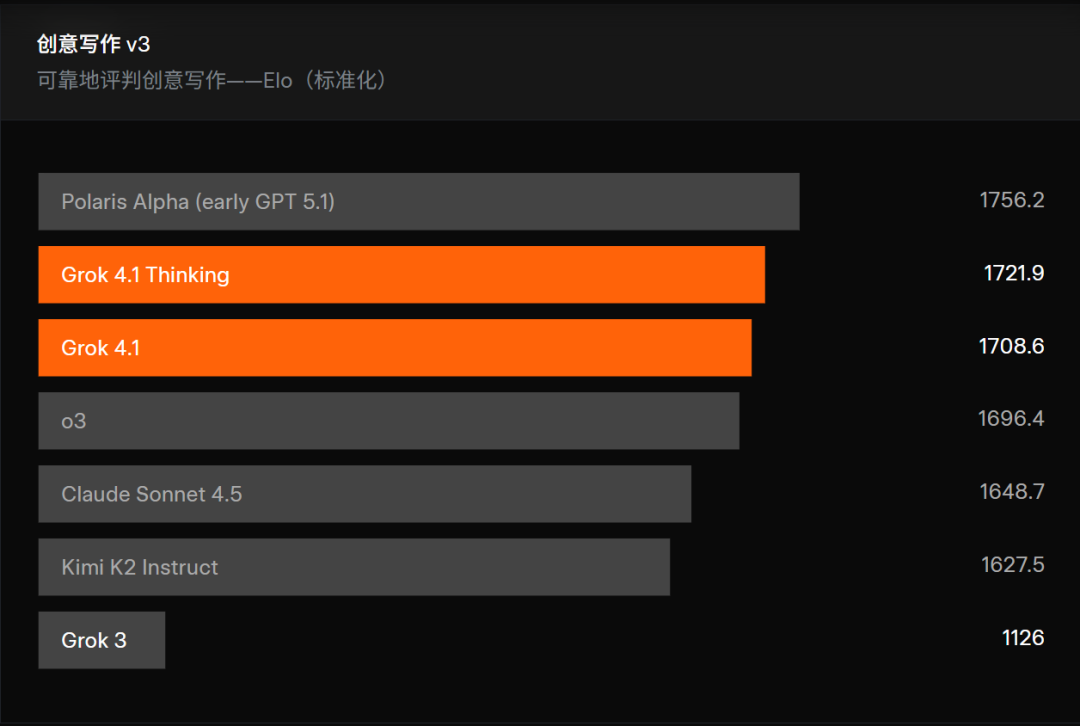
在这份榜单中,Grok 4.1 Thinking 和 Grok 4.1 占据第二、第三,两者之间仅收支十几分;而其他强势模子如 O3、Claude Sonnet 4.5、Kimi K2 以及旧版 Grok 3 齐被稳稳甩在背面,造成了澄澈的档位分层。
换句话说,Grok 4.1 还是参加全球最强“创意写稿梯队”。
而在官方给出的新旧版块对比中,咱们可以澄澈看出,Grok 4.1 已从“能写段子”的模子跃升为信得过具备体裁笔触的创作家:叙事更深、情绪更复杂、修辞更纯属、扮装更千里浸。

这些升级最终体当今 更好的交互体验 上。Grok 4.1 领有更领路的“个性”,对用户意图的贯通更详细,风作风节更当然。即便在非推理模式下,它也能领路输出高质料回答,同期保握极快反馈速率。
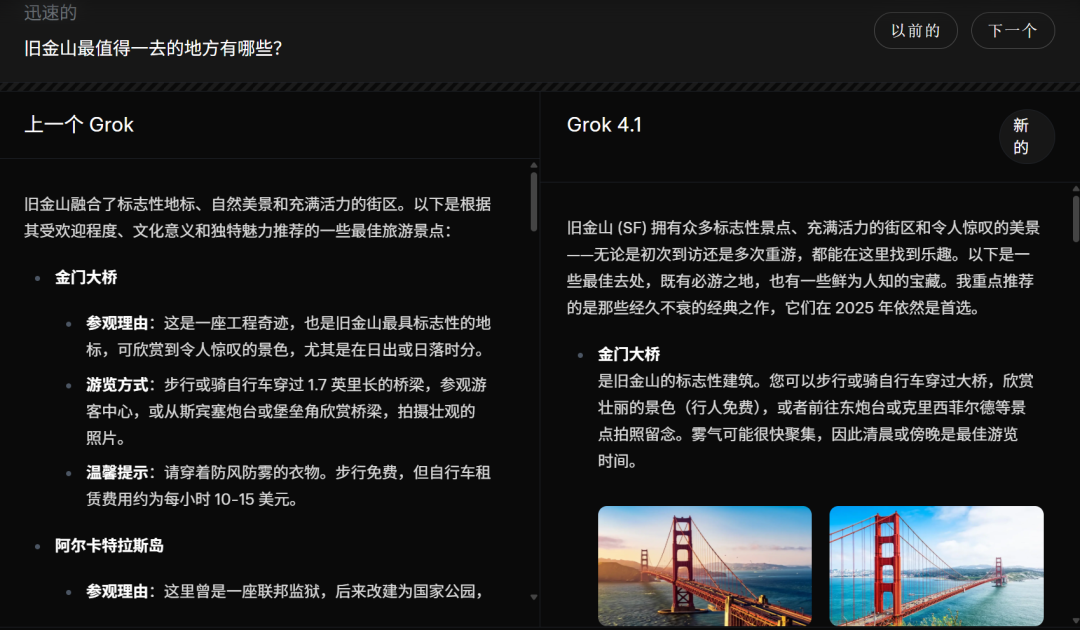
一个直不雅的例子是官方展示的旅游攻略对比。旧版 Grok 给出的内容像“百科式景点总览”,信息密度高但虚浮节律感;而 Grok 4.1 写旧金山,则像一位信得过“去过”“懂氛围”的腹地向导,会主动领导拍照时辰、保举恰当你的路子,致使带出城市的具体气质,更像在和一个真的的东说念主交流。
在复杂任务惩办中,Grok 4.1 的高下文窗口彭胀至 256K tokens,Fast 模式下更可达 200 万,使其在长文档贯通、握续互助与大型内容生成中保握高连贯度,显耀减少“断片”。
总体来看,Grok 4.1 的进步不是单点破损,而是从性能、事实性到情商、创意与交互体验的一次全维升级。
在发扬亮相之前,Grok 4.1 其实还是偷偷阅历了一轮为期两周的“静默发布”。从 2025 年 11 月 1 日到 14 日,xAI 将一部分真的用户流量在 grok.com、X 以及移动端诓骗中冉冉切换到 Grok 4.1,以不雅察它在真的环境下的阐扬。
这一阶段最直不雅的规矩,被澄澈地体当今那张 64.78% 的饼图上:在双盲对比、用户不知情的前提下,Grok 4.1 的回答有 64.78% 的概率被用户选为“更好”。换句话说,靠近一样的问题,用户在卓越六成的情况下更偏疼 Grok 4.1。
可以说,Grok 4.1 展现的更高的情绪贯通、更稳的事实性回话、更当然的交互魄力,齐通过静默测试被真的用户用投票“盖印”。

不管是 LMArena 双冠、幻觉率的断崖式下落,如故创意写稿与情谊智力的全面增强,新一代 Grok 已从“功能强”走向“体验强”,也为 xAI 在本年的大模子竞争中交出了一份极具劝服力的答卷。
咱们实测了 Grok4.1AI 前哨也上手实测了 Grok4.1。
当先是 推奢睿力 测试,咱们联想了一齐看似频频、骨子“有诈”(有 2 组解)的题(诸君可以我方脱手考据下):
“四个同学参加数学竞赛,永诀是:小 A、小 B、小 C、小 D。 比赛已毕后,他们对我方排行作念了如下四个判断:
(1)小 A 说:“我不是第又名。”
(2)小 B 说:“我也不是终末又名。”
(3)小 C 说:“我是第二名”
(4)小 D 说:“我才不是终末又名呢。”
已知:这四句中唯唯一句是实话,且四个东说念主排行两两不同。问:哪一句是实话?四个东说念主各自的排行若何?请给出推理经由。”
Grok 顺利找出了 2 组解,还主动成立题目 Bug。

不外需要理会的是,它其实在主动成立题目 Bug 时“翻车”了,Grok 建议,若是把小 C 说的话改为:“小 B 是第二名”,这么谜底就有唯一性。
但修改后,规矩其实还有多种:
第一,若是有唯独 B 在说实话,此时排行唯一笃信为 A1、C2、B3、D4;
第二,若是唯独 D 在说实话,此时只可笃信 A1、B4,C 和 D 永诀为第 2 第 3 名但不惟一。
再来望望 Grok 的写稿智力。
咱们给出了这么的 Prompt:
用讲故事的口气,准确且天真地、有感染力地证实马斯克 xAI 发布 Grok4.1 的事。条款字数:500-600 字,必须包含:发布时辰、居品亮点、商场布景等。
Grok4.1 的回答如下,还贴心肠统计了字数:578——然而,咱即是说,Grok 就怕是统计的英笔墨数(或者数学不好?),咱们手工用 Word 统计了字数:861 字。

终末,咱们测了一下 Grok4.1 的图像生成智力,恶果可以:Grok 根据一段 Prompt 生成了两张图,还真挺像真的相片的(不外细节嘛,寰球请自行评价)。

况兼还能径直根据图像,一键生成视频,恶果如下:

感酷爱酷爱的读者一又友们欧洲杯2024官网,也可以去上手试试。